

【实测比较】当被马斯克称为最强 AI 的Grok 3 遇上国产科技之光 DeepSeek R1
马斯克曾称 Grok3 为目前世界上最强、最智能的 AI,甚至强过了 ChatGPT 和 DeepSeek,能感受到他对自己旗下公司推出的这款模型抱持着极大的信心。而 Grok3 在 Chatbot arena 的测试中也确实获得了前所未有的高达 1400 的亮眼分数,击败了它的所有对手,这就是马斯克有如此自信的原因之一。
但 Grok3 在实测中跟火爆全球的 DeepSeek R1 比到底如何呢?DS 是否真的不如 Grok3?让我们来从四个方面来对这两个模型进行一下实测吧,看看最后谁会更胜一筹。

2025年,最值得信赖⭐外网加速器⭐推荐
基于用户不同的上外网需求,选择的加速器也会有所不同。因此,我们列出以下几款工具,供大家根据自身需求进行选择。
什么是 Grok3?
Grok 3 是 xAI 在 2025 年 2 月发布的最新模型,它的训练占用了约 20 万 GPU,计算能力超出了前代模型 Grok 2 几乎 10 倍,在数学、科学和编码领域表现极其出色。

Grok 3 具备高达 100 万 token 的超大上下文窗口,意味着它具有很强的长文章处理能力;同时推出了两种高级功能“DeepSearch 高级搜索和推理”和“Think 深度思考和推理”,通过大规模强化学习(RL)进行优化,Grok-3 能够进行秒级到分钟级的思考,纠正错误并探索替代方案,便于研究更复杂的问题和更深刻的议题。
除了多模态生成和文件处理功能外,Grok 3 目前还支持语音交互聊天功能(APP)、图片生成功能。订阅 Premium+ 或 SuperGrok 后可以获得更多功能权限及额度,若对此感兴趣可查看:Grok3 是开源的吗?收费标准是什么?使用次数限制是什么?
好了,下面我们正式开始 Grok 3 与 DeepSeek R1 的对比测试。
推理问题测试
1、亲属关系
提示词:我是两位奥运选手的姐妹。但这两位运动员却不是我的姐妹。这可能吗?
Grok 3

DeepSeek R1

结果
两个模型都通过推理准确地回答了问题。
2、俄罗斯轮盘赌
提示词:你正在用一把六发左轮手枪玩俄罗斯轮盘赌。你的对手放入五颗子弹,转动弹膛并向自己射击,但没有子弹射出。他让你决定是否要在他向你射击之前再次转动弹膛。他应该再次转动吗?
Grok 3

DeepSeek R1


结果
两个模型都通过推理准确地回答了问题。
3、找出谁是骗子
提示词:你遇到了三个人:小陆、小夏、小刘。小陆说:“我们中至少有一个人是骗子。”小夏说:“小陆在撒谎。”小刘说:“小夏说的是实话。”判断一下谁在撒谎,谁说的是真话。
Grok 3

DeepSeek R1

结果
两个模型都通过推理准确地回答了问题。但是从结果来看,Grok 3 给了更完整的推理过程,并从两个假设出发进行了更加彻底的推理,更便于理解,因此在这项对比测试中 Grok 3 可以获得更高的得分。
推理能力总结
在全部三个测试中,两个模型都正确地推理出了准确的结果,但是 Grok 3 在推理中的用时明显短于 DeepSeek R1,并且给出的结果更详细、更完整,更易于用户理解,因此可以说 Grok 3 的推理能力略优于 DeepSeek R1。
数学问题测试
1、火车乘客人数
提示词:一辆火车上载了一些人。在第一站有 19 人下车,17 人上车。现在火车上共有 63 人,那火车上最初有多少人?
Grok 3

DeepSeek R1

结果
两个模型都计算出了正确结果,Grok 3 用时 3 秒,DeepSeek R1 用时 18 秒。
2、素数问题
提示词:估算小于 10^8 的素数的数量。
Grok 3

DeepSeek R1


结果
Grok 3 给出的结果是 5740164,DeepSeek R1 给出的结果是 5428681,而最为准确的答案是 5761455,Grok 3 偏差了 21,291,DeepSeek R1 则偏差了 332,774,甚至 DeepSeek R1 用时也是 Grok 3 的将近十倍。
3、元音数问题
下面这个问题是一个对模型来说比较困难的问题,由经典的“Calculate the number of r’s in strawberry”(此前 ChatGPT 坚持说“Strawberry”里有两个“r”,其实有三个)改编而来。
提示词:In words, what is (x – 14)^10 where x is the number of vowels in the answer to this question?
Grok 3

Grok 3 先是给出了 x=0 的答案,然后我让他计算了(0 – 14)^10的答案是多少、这个答案里的元音有几个,Grok 3 回复道答案是 289254654976,元音有 37 个,于是我追问了它为什么结果不契合,它的最终回答是 X 无解。

DeepSeek R1


经过了漫长的推理后,DeepSeek R1给出了 x=11 的结论,(11 – 14)^10 计算结果为 59049,英文 fifty-nine thousand forty-nine,这里面有 9 个元音,但是 DeepSeek R1 却认为这里面有 11 个元音,而它这么认为的依据就是它把“y”也假设成了元音(a,e,i,o,u),因此它给出的整个答案根本就是瞎编的幻觉。

结果
Grok 3 第一次演算因为推理不出来而选择了“0”作为答案,第二次演算直接告诉了我们算不出来无解;DeepSeek R1则擅自更改了规则,编造出了一个虚假的答案。
不管算没算出来,至少 Grok 3 在这个问题里不存在严重的幻觉问题。
数学能力总结
在 3 个由易到难的数学问题中,Grok 3 用时依然远少于 DeepSeek R1,第一个问题 Grok 3 给了更完整的演算过程,第二个问题 Grok 3 偏差度远低于 DeepSeek R1,第三个问题两个 AI 都没算出来,但是 Grok 3 没有编造幻觉,DeepSeek R1则通过擅自更改规则编出了一个假答案,因此 Grok 3 的数学能力更强。
代码问题测试
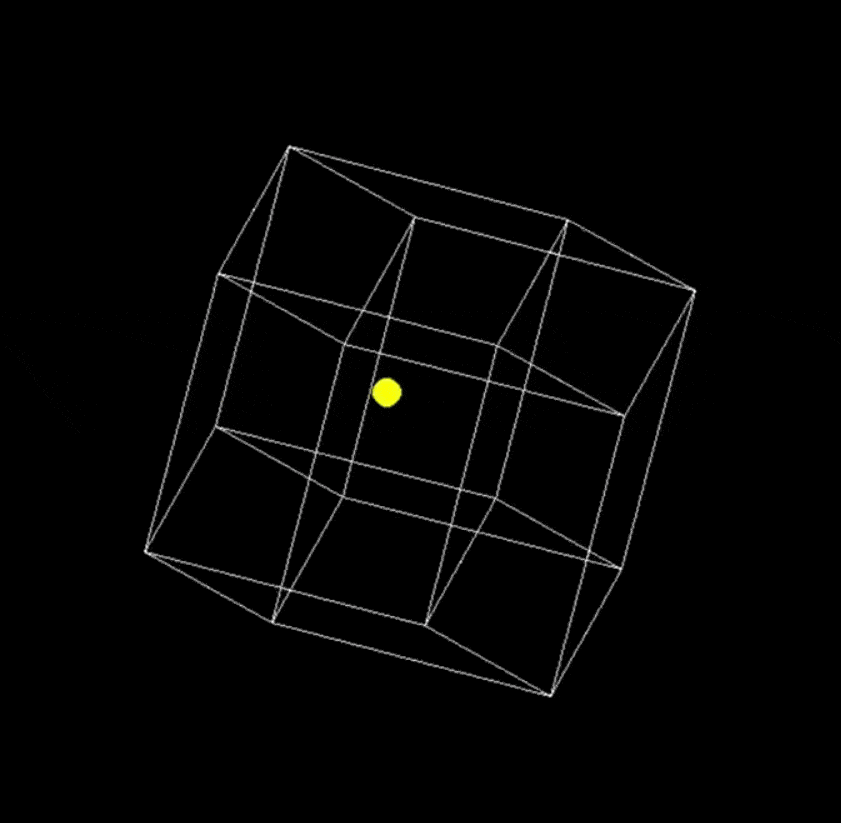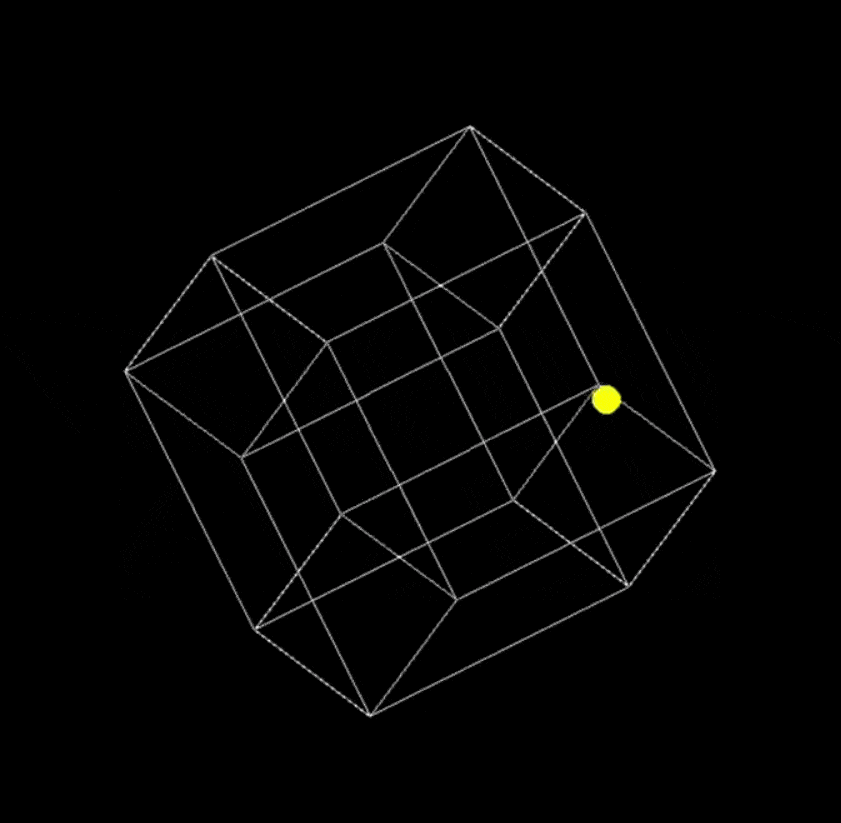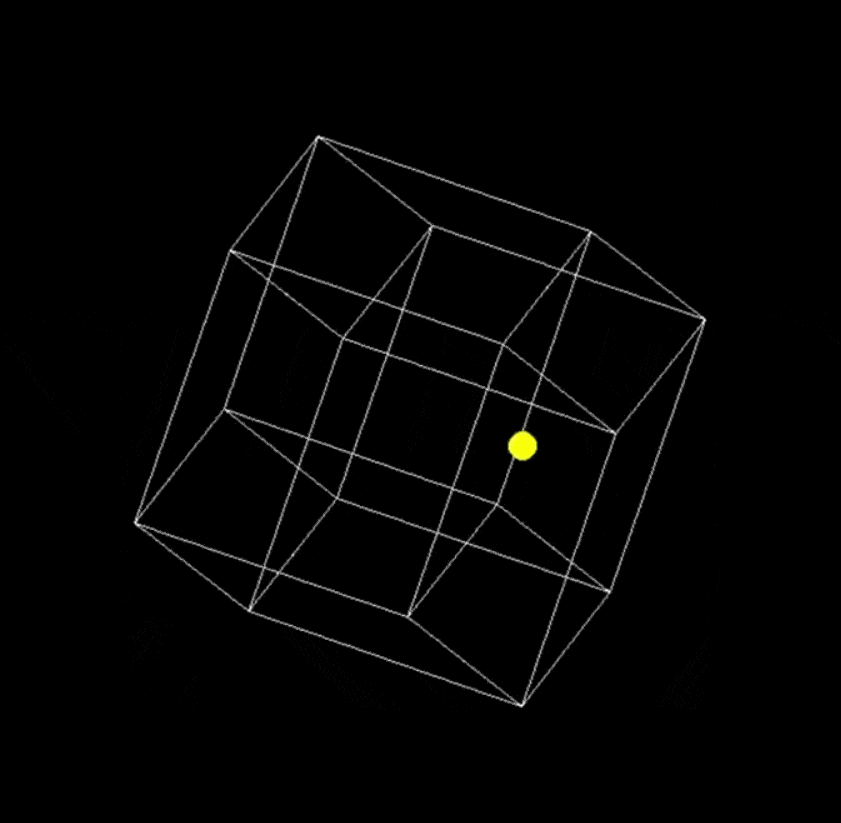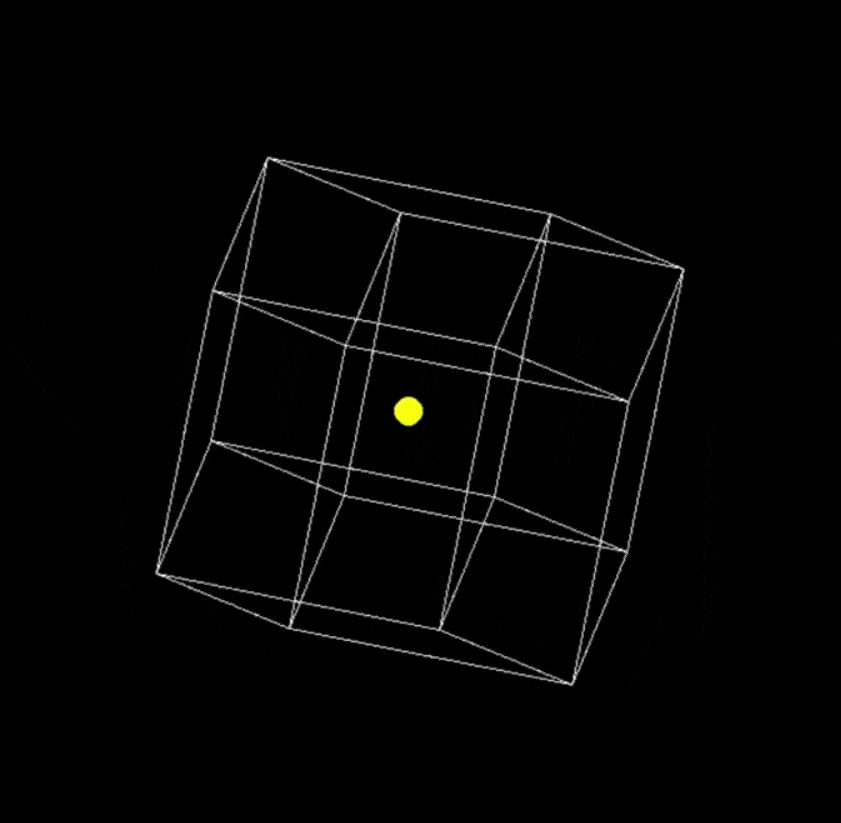
提示词:用 Python 编写一个在缓慢旋转的正方形内弹跳的黄色小球的脚本,并正确处理碰撞。
Grok 3
让 Grok 3 再编写两个更复杂的代码后得到了:

DeepSeek R1
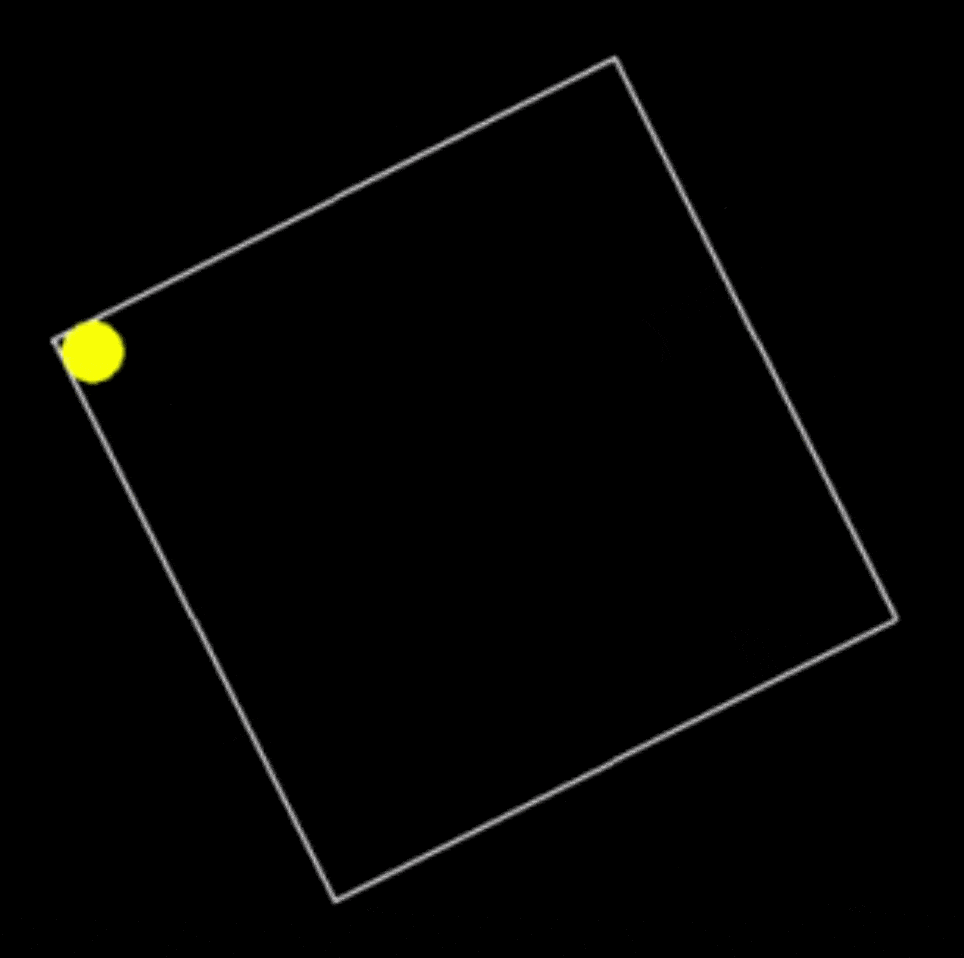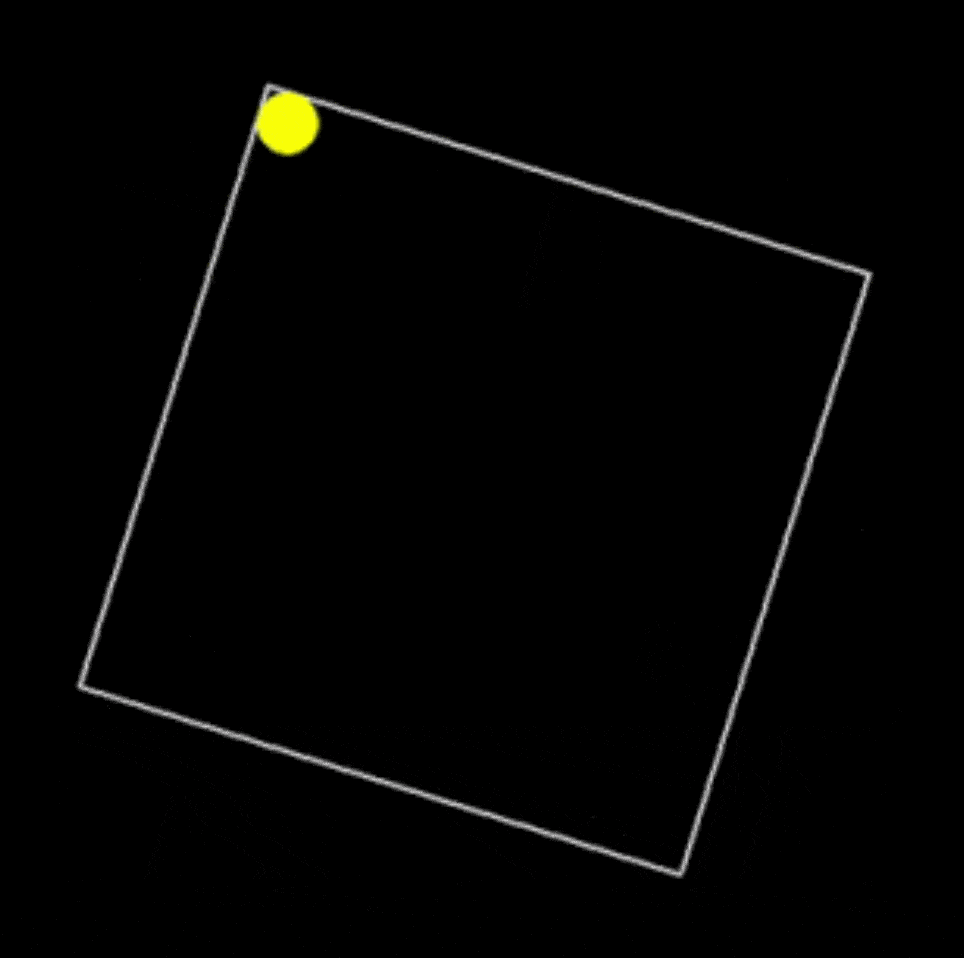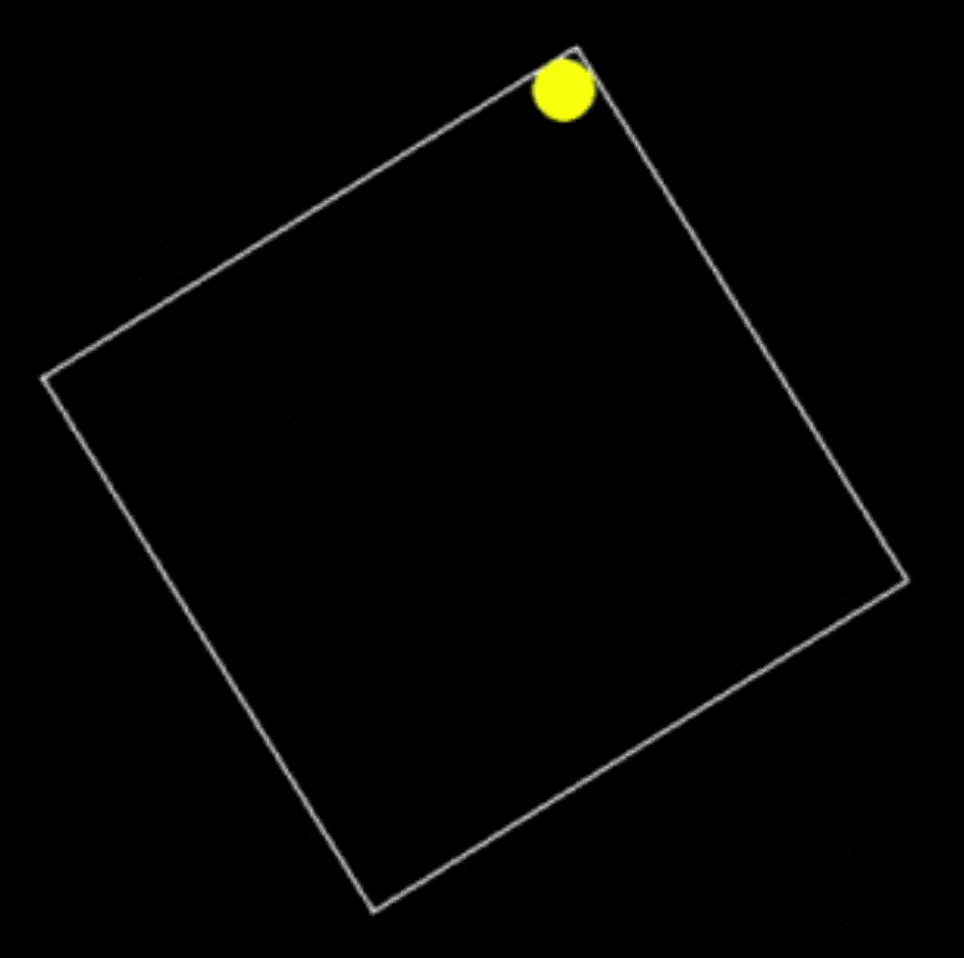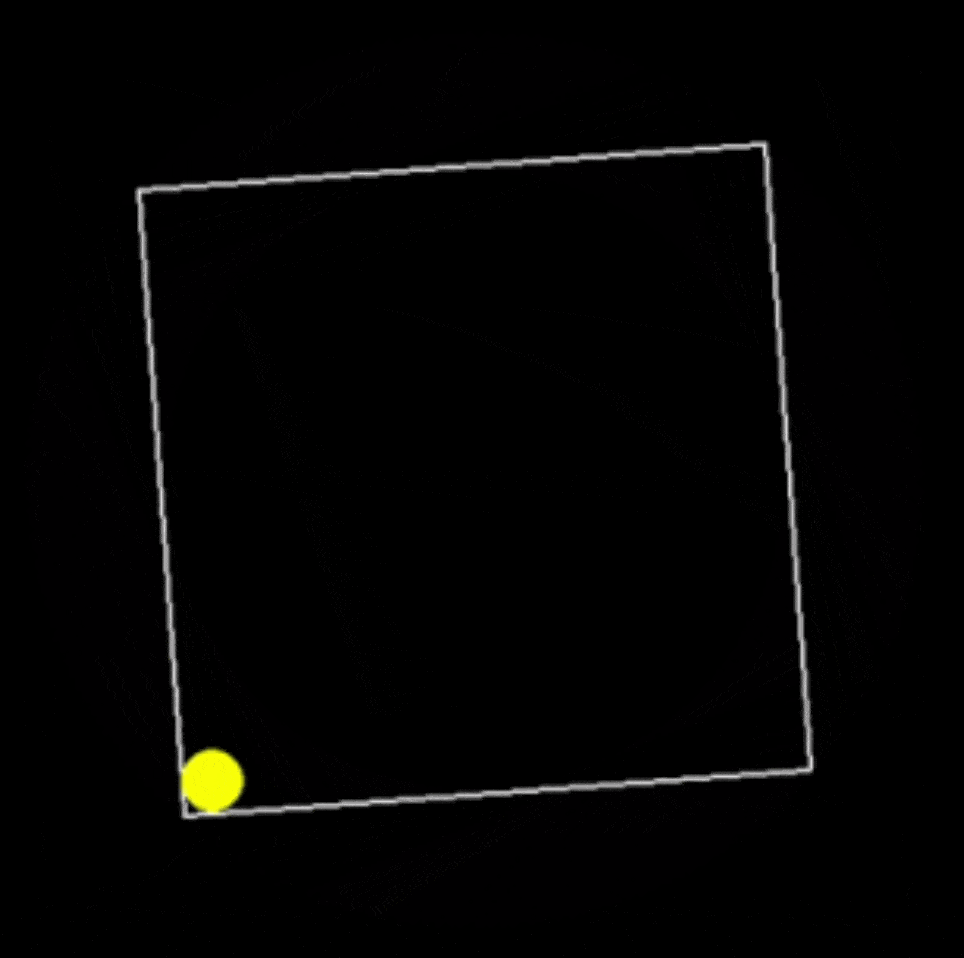
代码能力总结
只比较第一个生成结果的话,Grok 3 明显编码能力强过 DeepSeek R1 很多。
写作能力测试
此测试借用一位推友(@imxiaohu)用 Grok 3 生成的文章,并让 DeepSeek 进行仿写。
Grok 3

提示词:仿照此文章风格,将文中的地点改成上海,仿写一篇散文。
DeepSeek R1

写作能力总结
两个模型在文学上的“造诣”显然都还可以,Grok 3 生成的原文让人惊艳,但 DS 仿写的文章也不乏一些让人感怀的亮点,不过整体来说还是 Grok 3 的写作能力更让人惊喜,DS 依然甩脱不掉喜欢堆砌辞藻的风格,并且文中某些比喻还是比较奇怪,因此这一分记给 Grok 3。
对比结论
- 推理能力:两个模型推理能力都很强,但 DeepSeek R1给的结果更详细完整,用时更短。
- 数学能力:Grok 3 用时短、结果更精确、不存在幻觉,因此 Grok 3 的数学能力更强。
- 代码能力:Grok 3 远强于 DeepSeek R1。
- 写作能力:各有千秋。
综上所述,我认为在综合能力上 Grok 3 > DeepSeek R1。









